awk 系列:如何使用 awk 内置变量
| 2016-08-08 19:15:19 评论: 0
我们将逐渐揭开 awk 功能的神秘面纱,在本节中,我们将介绍 awk 内置 变量的概念。你可以在 awk 中使用两种类型的变量,它们是: 用户自定义 变量(我们在第八节中已经介绍了)和内置变量。

awk 内置变量示例
awk 内置变量已经有预先定义的值了,但我们也可以谨慎地修改这些值,awk 内置变量包括:
FILENAME: 当前输入文件名称NR: 当前输入行编号(是指输入行 1,2,3……等)NF: 当前输入行的字段编号OFS: 输出字段分隔符FS: 输入字段分隔符ORS: 输出记录分隔符RS: 输入记录分隔符
让我们继续演示一些使用上述 awk 内置变量的方法:
想要读取当前输入文件的名称,你可以使用 FILENAME 内置变量,如下:
$ awk ' { print FILENAME } ' ~/domains.txt
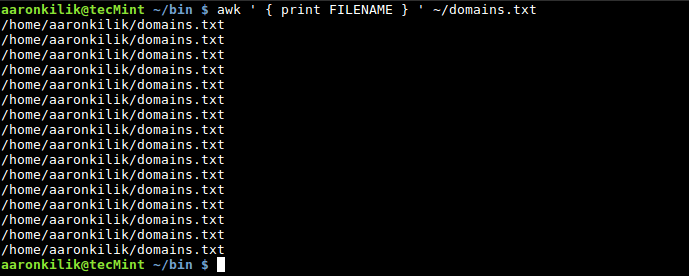
awk FILENAME 变量
你会看到,每一行都会对应输出一次文件名,那是你使用 FILENAME 内置变量时 awk 默认的行为。
我们可以使用 NR 来统计一个输入文件的行数(记录),谨记,它也会计算空行,正如我们将要在下面的例子中看到的那样。
当我们使用 cat 命令查看文件 domains.txt 时,会发现它有 14 行文本和 2 个空行:
$ cat ~/domains.txt
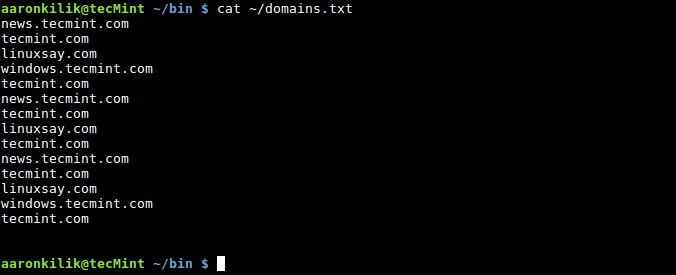
输出文件内容
$ awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt

awk 统计行数
想要统计一条记录或一行中的字段数,我们可以像下面那样使用 NR 内置变量:
$ cat ~/names.txt
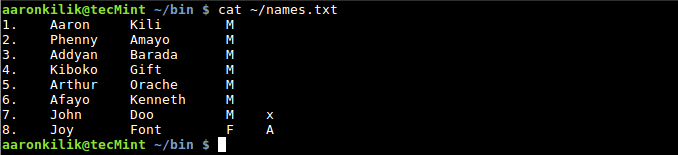
列出文件内容
$ awk '{ "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
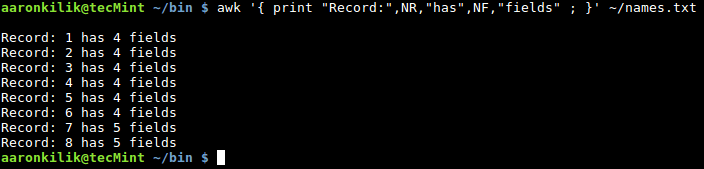
awk 统计文件中的字段数
接下来,你也可以使用 FS 内置变量指定一个输入文件分隔符,它会定义 awk 如何将输入行划分成字段。
FS 默认值为“空格”和“制表符”,但我们也能将 FS 值修改为任何字符来让 awk 根据情况切分输入行。
有两种方法可以达到目的:
- 第一种方法是使用 FS 内置变量
- 第二种方法是使用 awk 的 -F 选项
来看 Linux 系统上的 /etc/passwd 文件,该文件中的各字段是使用 : 分隔的,因此,当我们想要过滤出某些字段时,可以将 : 指定为新的输入字段分隔符,示例如下:
我们可以使用 -F 选项,如下:
$ awk -F':' '{ print $1, $4 ;}' /etc/passwd
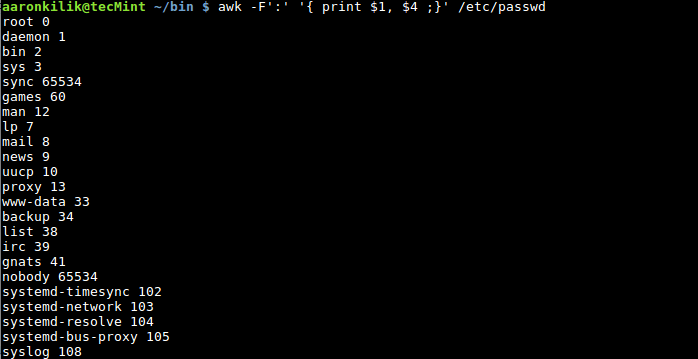
awk 过滤密码文件中的各字段
此外,我们也可以利用 FS 内置变量,如下:
$ awk ' BEGIN { FS=“:” ; } { print $1, $4 ; } ' /etc/passwd
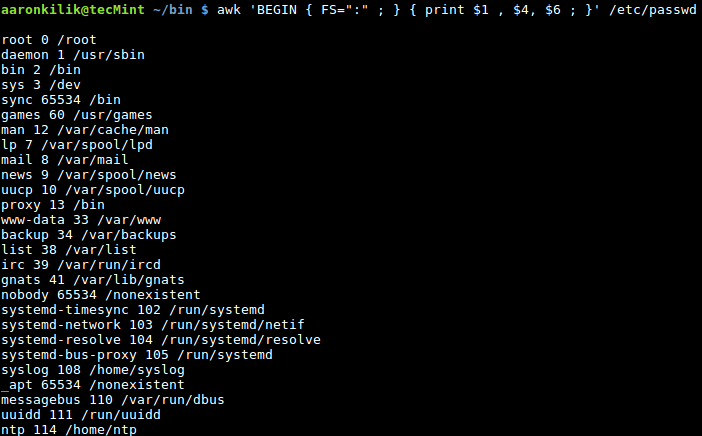
使用 awk 过滤文件中的各字段
使用 OFS 内置变量来指定一个用于输出的字段分隔符,它会定义如何使用指定的字符分隔输出字段,示例如下:
$ awk -F':' ' BEGIN { OFS="==>" ;} { print $1, $4 ;}' /etc/passwd
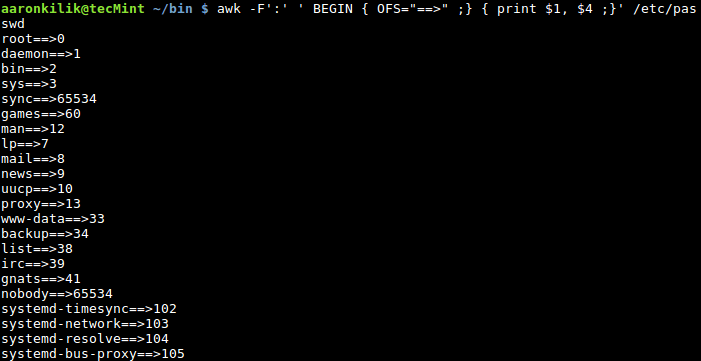
向文件中的字段添加分隔符
在本节中,我们已经学习了使用含有预定义值的 awk 内置变量的理念。但我们也能够修改这些值,虽然并不推荐这样做,除非你明白自己在做什么,并且充分理解(这些变量值)。
此后,我们将继续学习如何在 awk 命令操作中使用 shell 变量,所以,请继续关注我们。
